Hướng dẫn thiết lập SQL Server để kết nối từ xa qua mạng Internet
Hướng dẫn cài đặt và cấu hình SQL Server để kết nối từ xa qua Internet
Hệ quản trị cơ sở dữ liệu Microsoft SQL Server của Microsoft được đánh giá là một trong những hệ quản trị cơ sở dữ liệu tốt và mạnh nhất hiện nay. Nếu bạn là một nhà phát triển ứng dụng cũng như phát triển website trên môi trường Windows thì không thể không biết đến SQL Server.
Khi phát triển các ứng dụng dạng Desktop thì chúng ta thường không quan tâm và thậm chí có thể không cần biết đến tính năng hỗ trợ kết nối từ xa của SQL Server. Nhưng khi bạn phát triển các ứng dụng Web, hoặc các ứng dụng desktop đòi hỏi dữ liệu tập trung tức thì để phục vụ cho việc ra báo cáo mà chương trình thì lại cách xa nhau về mặt địa lý, thì bạn sẽ cần đến tính năng kết nối từ xa của SQL Server. Tính năng này có trên tất cả các phiên bản SQL Server.
Trong bài viết này, tôi thực hiện hướng dẫn cài đặt và cấu hình trên phiên bản SQL Server 2005, các phiên bản khác việc thực hiện tương tự.
Sau khi hoàn thành bài hướng dẫn này:
Bạn có thể cài đặt SQL ServerBạn có kết nối vào SQL Server cài trên máy tính của bạn từ bất kỳ máy tính nào có nối mạng Internet từ bất cứ đâu.
Các bước thực hiện
Cài đặt SQL Server
Cấu hình SQL Server để mở kết nối từ xa.
Tạo user kết nối
Cấu hình Firewall trên Server cho phép nhận kết nối đến qua cổng kết nối của SQL Server
Cấu hình Router cho phép kết nối đến thông qua cổng của kết nối SQL Server
· Bước 1: Cài đặt SQL Server
* Xem hướng dẫn cài đặt SQL Server 2005 tại link này :http://bis.net.vn/forums/t/47.aspx
· Bước 2: Config SQL Server cho phép kết nối từ xa
Mục đích là kích hoạt tính năng cho phép kết nối từ xa của SQL Server và thiết lập cổng nghe (Listenning Port) cho SQL Server.
Vào Start -> All Programs -> Microsoft SQL Server 2005 -> Configuration Tools -> SQL Server Configuration Manager
Ở menu bên trái, chọn vào mục SQL Server 2005 Services -> Bên phải tìm mục SQL Server (MSSQLSERVER) (chú ý đây là dịch vụ cơ bản của SQL Server, tên của nó tùy thuộc vào Instant của SQL mà bạn cài vào máy, của tôi là MSSQLSERVER, có thể Instant của bạn sẽ khác). Click phải vào và chọn Properties (xem hình)

Trong Tab Log On, click chọn vào Built-In Account, chọn vào Network Service như trong hình, Click OK

Quay lại màn hình SQL Server Configuration Manager -> ở menu bên trái tiếp tục click vào mục SQL Server 2005 Network Configuration để mở ra menu con Protocols for MSSQLSERRVER(tên trên máy bạn có thể khác), chọn vào mục này -> bên phải tìm mục có tên là TCP/IP, click phải vào nó và chọn Properties (xem hình)

Trong cửa sổ mở ra, ở Tab Protocols, mục Enabled chọn vào Yes

Tiếp tục click qua Tab IP Address -> Sẽ xuất hiện list các IP (IP1, IP2,…) đây là danh sách các IP hình thành khi máy bạn có kết nối vào các mạng LAN khác nhau

Hãy chọn một IP nào đó bất kỳ (ví dụ tôi chọn IP1)
· Ở mục IP Address bạn xóa đi và gõ lại địa chỉ IP của máy bạn trong mạng LAN (chú ý đây là địa chỉ IP của máy bạn trong mạng LAN – ví dụ của tôi là 192.168.1.2)
· Ở mục Active - chọn Yes, mục Enabled - chọn Yes
· Ở mục TCP Port, khai báo cổng share mặc định của SQL, bạn có thể để mặc định là 1433
· Click OK
Restart lại SQL Server. (bằng cách chọn vào mục SQL Server 2005 Services, bên phải click phải vào mục SQL Server (MSSQLSERVER) -> Chọn Restart)
· Bước 3: Tạo một user để thực hiện kết nối từ xa
Mở Start -> All Programs -> Microsoft SQL Server 2005 -> SQL Server Management Studio -> Connect vào Server
Ở menu bên trái, mở mục Security -> Login -> Nhấn chuột phải và chọn New Login

Gõ vào Tên User, Password như trong hình, bỏ dấu ở mục Enforce password Expiration -> Nhấn OK

· Bước 4: Cấu hình Firewall cho phép nhận kết nối đến qua cổng share của SQL Server
Mục đích của việc này là để mở cổng Firewall của Windows cho phép nhận kết nối từ bên ngoài qua cổng share của SQL, mặc định là cổng 1433
* Trên WindowsXP
· Vào Control Panel -> Windows Firewall
· Trong Tab Exceptions, click vào nút Add Port để thêm cổng 1433
· Hộp thoại Add Port hiện ra, trong mục Name gõ tên bất kỳ, Port Number gõ số 1433, click chọn vào mục TCP (xem hình dưới)
· Nhấn OK
· Log Off hoặc Restart lại máy

* Trên Windows Vista, Windows 7:
Vào Start -> Control Panel -> Windows Firewall -> Ở menu bên trái chọn Advanced settings
Menu bên trái, click vào mục Inbound Rules
Tiếp tục ở Menu bên phải, click vào mục New Rule
Trong cửa sổ mới hiện ra, đánh dấu vào mục Port như hình -> Nhấn Next

Tiếp theo nhấn chọn vào mục TCP và Specific local Ports, gõ vào 1433 (số cổng share của SQL Server đã config trong bước 2) -> Nhấn Next

Trên màn hình tiếp theo, đánh dấu chọn vào mục Allow the connection -> Nhấn Next

Trong màn hình tiếp theo, chọn kiểu mạng sẽ áp dụng mở cổng này, đánh dấu vào cả 3 mục Domain, Private, Public -> Nhấn Next

Trong màn hình tiếp theo, gõ tên kết nối và Description tùy ý -> Nhấn Finish

Log Off hoặc Restart lại máy
· Bước 5: Cấu hình Router cho phép kết nối qua Port 1433
Mục đích của việc này:
· Mở cổng của Router trên mạng của bạn để cho phép nhận kết nối từ bên ngoài mạng (từ Internet) qua cổng kết nối của SQL Server (Port 1433).
· Chuyển hướng (Forward) kết nối về đến đúng máy mà bạn làm Server khi Router nhận được yêu cầu qua cổng 1433
Tùy loại Router mà bạn đang sử dụng, việc cấu hình có thể khác nhau đôi chút. Ở đây tôi đang thực hiện config trên một loại Router của Dlink. Các loại Router khác bạn có thể tự tìm hiểu thêm. Cách thiết lập trên các loại Router cơ bản là giống nhau, chỉ khác nhau về cách bố trí trên menu thôi.
Đầu tiên mở IE ra và gõ địa chỉ của Gateway -> Enter và đăng nhập vào quản trị Router
Ví dụ: Gateway của tôi là 192.168.1.1 thì tôi gõ vào Address của IE làhttp://192.168.1.1 -> Enter
Hãy đọc hướng dẫn sử dụng kèm theo router của bạn để biết được địa chỉ gateway cũng như user và password đăng nhập vào quản trị.
Menu bên trái, chọn Advanced Setup -> NAT -> Virtual Servers
Click Add và thiết lập như trong hình -> Save

Hãy chú ý các mục mà tôi đánh dấu:
· Custom Server: Tên của thiết lập, do bạn tự đặt tùy ý
· Server IP Address: Đây là địa chỉ IP của máy mà bạn cài làm máy chủ. Ví dụ của tôi là 192.168.1.2
Chú ý: Đây chính là IP của máy mà yêu cầu sẽ được Router chuyển đến. Do đó bạn nên khai báo IP tĩnh cho máy bạn cài làm máy chủ để khỏi phải vào mục này thiết lập lại mỗi khi restart máy.
Xin nhớ rằng đây là IP của máy trong mạng LAN chứ không phải là IP đối với mạng Internet.
· Port Start, Port End là số hiệu của cổng nhận yêu cầu, đều khai báo là 1433
Ở đây sở dĩ có Port Start và Port End là vì Router cho phép bạn Forward trong cả một dải các cổng (từ cổng đến cổng). Đối với kết nối SQL Server chúng ta đang thực hiện thì chỉ cần Port 1433 thôi. Một số loại router có mục Single Port Forwarding – cho phép bạn chỉ cần config một cổng thôi là đủ.
· Mục Protocol: Chọn phương thức kết nối là TCP.
Chú ý: Thường thì phần thiết lập này nằm trong mục NAT (Network Address Translation), hoặc có thể là Port Forwarding,… tùy router.
Đến đây bạn đã hoàn thành việc cài đặt và cấu hình cho phép server nhận kết nối SQL Server từ xa qua cổng 1433.
Để test kết quả:
· Hãy ngồi ở một máy tính nào đó ngoài mạng LAN của bạn, có kết nối Internet.
· Dùng một chương trình quản lý SQL Server (có thể dùng SQL Server Management Studio), gõ vào các thông tin kết nối -> Nhấn Connect
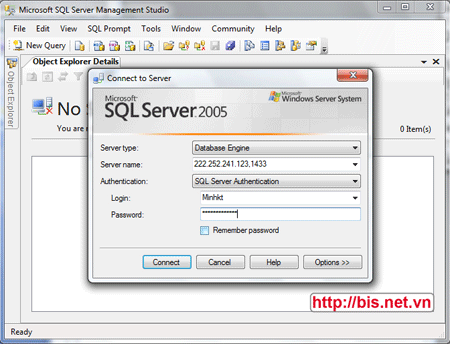
Chú ý một số thông tin:
- 1. Server name: Đây là địa chỉ của Server nhận kết nối (chính là máy bạn đã cài SQL). Trong hình tôi gõ là 222.252.241.123,1433. Trong đó 222.252.241.123 chính là địa chỉ IP của máy tôi ở trên Internet, 1433 là cổng (Port) share SQL Server của tôi (tùy cổng share của bạn thiết lập, số này có thể khác, nếu bạn dùng 1433 thì có thể không cần gõ vì đây là cổng mặc định)
- 2. Authentication: Chọn kiểu chứng thực người dùng, có hai chế độ chứng thực là Windows Authentication và SQL Server Authentication. Tuy nhiên để kết nối từ xa thì phải dùng SQL Server Authentication
- 3. Login: Gõ user name mà bạn đã tạo
- 4. Password: Mật khẩu tương ứng